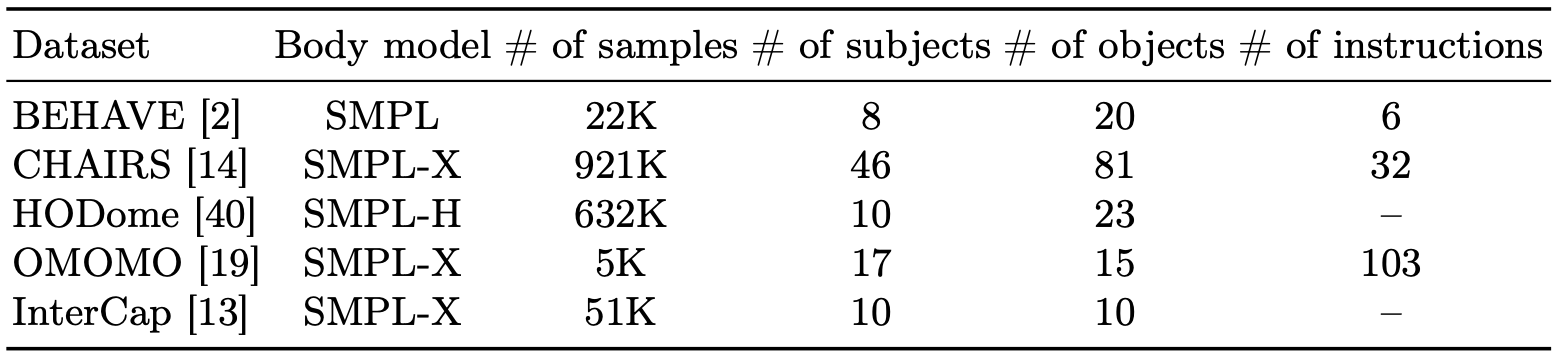
Dataset Configuration
We utilize 5 datasets with various human-object interactions. All of the datasets contain everyday objects that are frequently interacted on the road by humans.
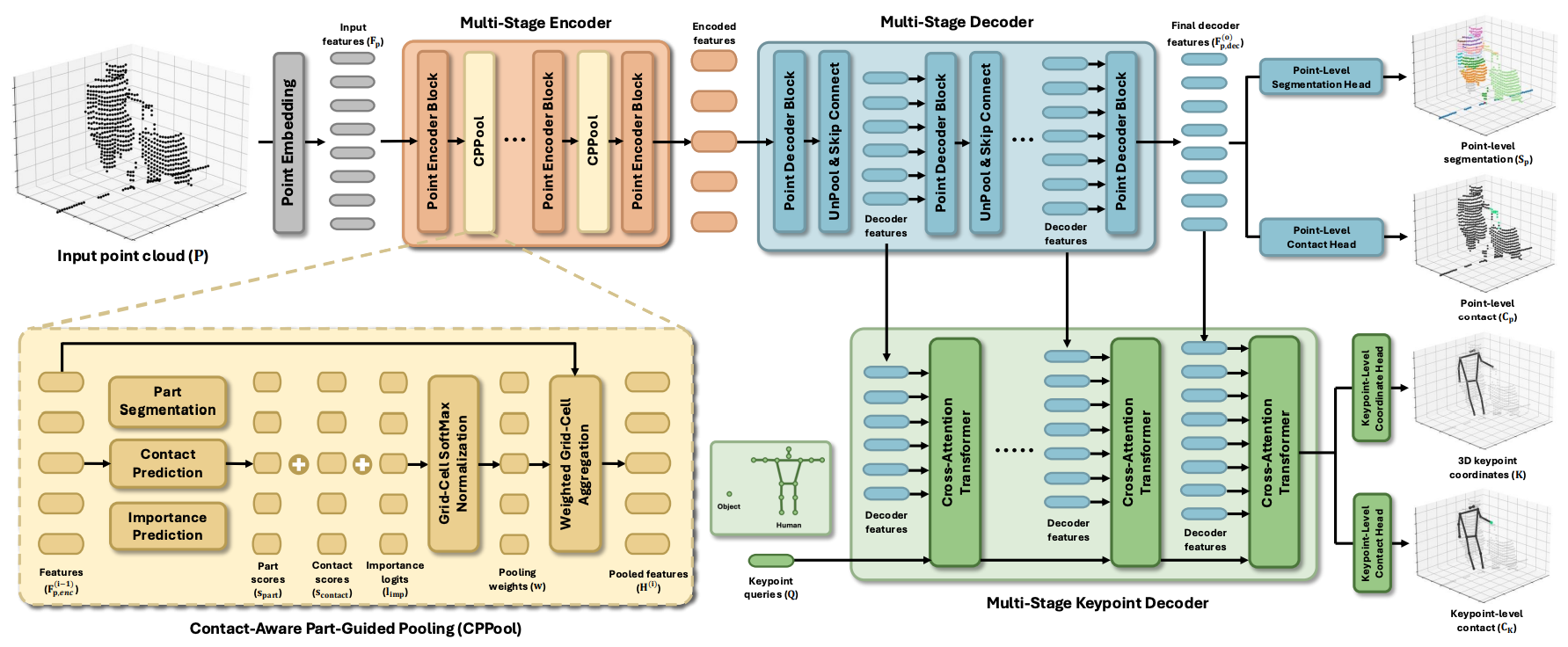
Model Architecture
Given an input point cloud, we first embed it into input features and encode them using a multi-stage encoder with CPPool. The encoded features are then progressively decoded through a multi-stage decoder to produce the final decoder features. At each decoding stage, keypoint queries are iteratively updated via multi-stage keypoint decoder with decoder features. Lastly, HOIL predicts point-level segmentation and contact from the final decoder feature, and 3D keypoint coordinates and keypoint-level contact from keypoint queries.
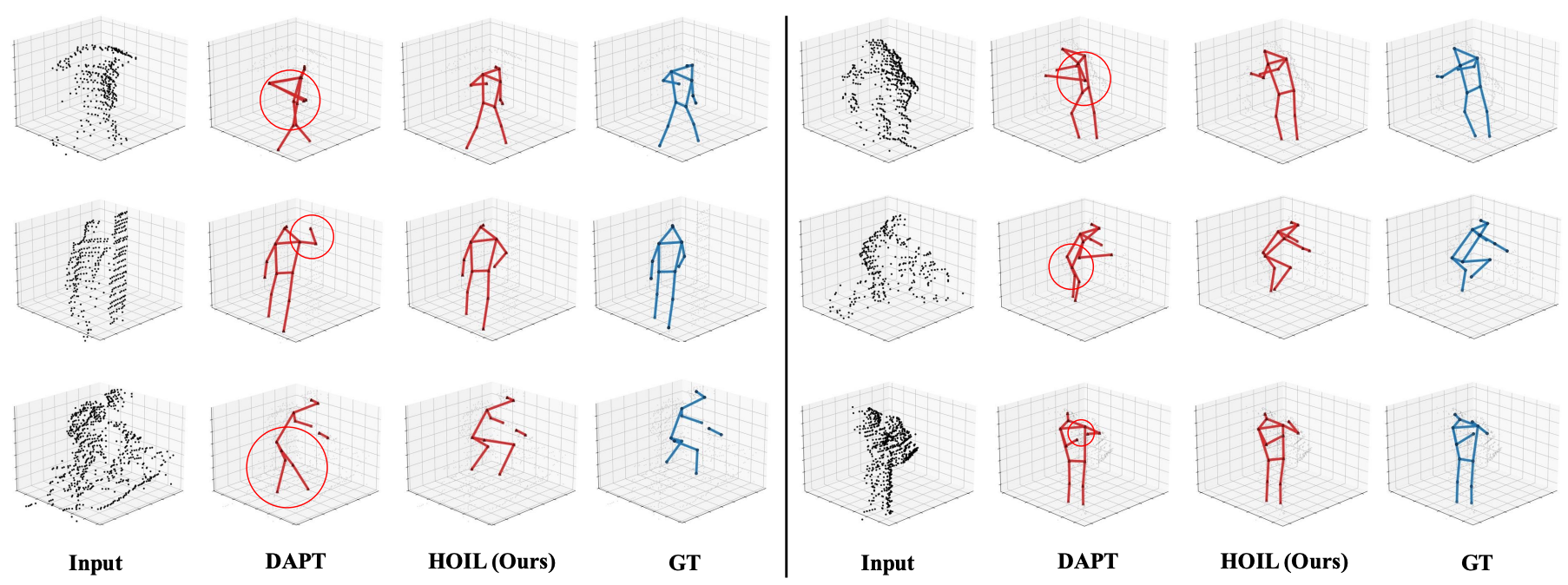
Qualitative Results
Related Links
There's a lot of excellent works that we wish to share.
Pre-training a Density-Aware Pose Transformer for Robust LiDAR-based 3D Human Pose Estimation.
Use All The Labels: A Hierarchical Multi-Label Contrastive Learning Framework.
Targeted Supervised Contrastive Learning for Long-Tailed Recognition.
Joint Reconstruction of 3D Human and Object via Contact-Based Refinement Transformer.